Stories



-
![نبض الملاعب]()
نبض الملاعب
RT STORIES
أعلى من راتب صلاح بكثير.. ليفربول يجهز عرضا مغريا لضم جناح "طائر"
![أعلى من راتب صلاح بكثير.. ليفربول يجهز عرضا مغريا لضم جناح "طائر"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيس الجزائر يهنئ البطلة كيليا نمور عقب تألقها في مصر
![رئيس الجزائر يهنئ البطلة كيليا نمور عقب تألقها في مصر]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رئيس الكونغو الديمقراطية يمنح مكافآت ضخمة للاعبي بلاده بعد إنجازا طال انتظاره 52 عاما (فيديو)
![رئيس الكونغو الديمقراطية يمنح مكافآت ضخمة للاعبي بلاده بعد إنجازا طال انتظاره 52 عاما (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بانتظار "زملكاوي".. بيان رسمي من الزمالك يحذر فيه من التطبيقات
![بانتظار "زملكاوي".. بيان رسمي من الزمالك يحذر فيه من التطبيقات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
طلب رسمي من لاعبي الكونغو لرئيس الجمهورية بشأن المشجع الشهير "لومومبا".. فيديو
![طلب رسمي من لاعبي الكونغو لرئيس الجمهورية بشأن المشجع الشهير "لومومبا".. فيديو]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الروسي مارينوف يفوز بذهبية بطولة كأس العالم للجمباز في مصر (فيديو)
![الروسي مارينوف يفوز بذهبية بطولة كأس العالم للجمباز في مصر (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
النجمة الجزائرية كيليا نمور تواصل انتصاراتها في كأس العالم للجمباز
![النجمة الجزائرية كيليا نمور تواصل انتصاراتها في كأس العالم للجمباز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وزير الرياضة الكونغولي يتوعد الأسطورة رونالدو بـ"البكاء" في كأس العالم
![وزير الرياضة الكونغولي يتوعد الأسطورة رونالدو بـ"البكاء" في كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بخصوص العنصرية.. رسالة هامة من فينيسيوس جونيور للامين جمال (فيديو)
![بخصوص العنصرية.. رسالة هامة من فينيسيوس جونيور للامين جمال (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
موقف هاري كين من مباراة بايرن ميونخ وريال مدريد في دوري أبطال أوروبا (فيديو)
![موقف هاري كين من مباراة بايرن ميونخ وريال مدريد في دوري أبطال أوروبا (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مفاجأة.. إمام عاشور على رادار نادي إنجليزي
![مفاجأة.. إمام عاشور على رادار نادي إنجليزي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"العدو اللدود" يتغنى.. كاراغر يودع محمد صلاح بكلمات مؤثرة
!["العدو اللدود" يتغنى.. كاراغر يودع محمد صلاح بكلمات مؤثرة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حرق علم هيرتا برلين.. أحداث شغب وفوضى عارمة في الدوري الألماني (فيديو)
![حرق علم هيرتا برلين.. أحداث شغب وفوضى عارمة في الدوري الألماني (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الروسي روبليف يبدأ بنجاح رحلته في موناكو (فيديو)
![الروسي روبليف يبدأ بنجاح رحلته في موناكو (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
من بينها فريقان سعوديان.. وجهة البرتغالي برناردو سيلفا بعد إعلان رحيله عن مانشستر سيتي
![من بينها فريقان سعوديان.. وجهة البرتغالي برناردو سيلفا بعد إعلان رحيله عن مانشستر سيتي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"اتخذوا قرارا لا يصدقه عقل".. شوبير ينتقد إدارة الأهلي
!["اتخذوا قرارا لا يصدقه عقل".. شوبير ينتقد إدارة الأهلي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
اقتراح إنجليزي ينقل صلاح إلى الهلال في صفقة تبادلية مع ليفربول
![اقتراح إنجليزي ينقل صلاح إلى الهلال في صفقة تبادلية مع ليفربول]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
باريس سان جيرمان يقدم عرضا ضخما لضم نجم من برشلونة
![باريس سان جيرمان يقدم عرضا ضخما لضم نجم من برشلونة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
جماهير العراق في مأزق.. فرحة التأهل لمونديال 2026 تصطدم بأزمة التذاكر
![جماهير العراق في مأزق.. فرحة التأهل لمونديال 2026 تصطدم بأزمة التذاكر]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فازوا ثم اختفوا!.. ماذا حدث لنجوم إريتريا بعد مباراة في تصفيات أمم إفريقيا؟
![فازوا ثم اختفوا!.. ماذا حدث لنجوم إريتريا بعد مباراة في تصفيات أمم إفريقيا؟]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![نبض الملاعب]() نبض الملاعب
نبض الملاعب
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
خبير: الناتو قد يجد نفسه متورطا في حرب نووية بسبب أوكرانيا
![خبير: الناتو قد يجد نفسه متورطا في حرب نووية بسبب أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روسيا تحذر دول البلطيق من فتح المجال الجوي للطائرات المسيرة الأوكرانية
![روسيا تحذر دول البلطيق من فتح المجال الجوي للطائرات المسيرة الأوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
برلماني سابق: الحرب الأهلية في أوكرانيا قد تندلع من أي شرارة والمجزرة قادمة لا محالة
![برلماني سابق: الحرب الأهلية في أوكرانيا قد تندلع من أي شرارة والمجزرة قادمة لا محالة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: تضرر مرافق لـ"اتحاد خط أنابيب بحر قزوين" في نوفوروسييسك بهجوم مسيرات أوكرانية
![الدفاع الروسية: تضرر مرافق لـ"اتحاد خط أنابيب بحر قزوين" في نوفوروسييسك بهجوم مسيرات أوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الأمن الروسي: توقيف مواطن كان يخطط لهجوم إرهابي ضد مسؤول رفيع المستوى في كورسك
![الأمن الروسي: توقيف مواطن كان يخطط لهجوم إرهابي ضد مسؤول رفيع المستوى في كورسك]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سفير روسيا في لندن : بريطانيا معنية بتصعيد الصراع في أوكرانيا
![سفير روسيا في لندن : بريطانيا معنية بتصعيد الصراع في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إسقاط 148 مسيرة أوكرانية خلال 3 ساعات فوق عدة مقاطعات روسية
![إسقاط 148 مسيرة أوكرانية خلال 3 ساعات فوق عدة مقاطعات روسية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: إسقاط 58 مسيرة أوكرانية خلال 6 ساعات فوق عدة مقاطعات
![الدفاع الروسية: إسقاط 58 مسيرة أوكرانية خلال 6 ساعات فوق عدة مقاطعات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ليخاتشيف: انقطاع التيار الكهربائي عن محطة زابورجيه النووية عبر خط "دنيبروفسكايا"
![ليخاتشيف: انقطاع التيار الكهربائي عن محطة زابورجيه النووية عبر خط "دنيبروفسكايا"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الروسي يضرب مطارات عسكرية أوكرانية ومواقع للطاقة مرتبطة بالجيش الأوكراني
![الجيش الروسي يضرب مطارات عسكرية أوكرانية ومواقع للطاقة مرتبطة بالجيش الأوكراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![ضربات إسرائيلية على لبنان]()
ضربات إسرائيلية على لبنان
RT STORIES
إعلام إسرائيلي يكشف أسباب هروب الجنود الإسرائيليين وإلغاء عملية التقدم شمال نهر الليطاني جنوب لبنان
![إعلام إسرائيلي يكشف أسباب هروب الجنود الإسرائيليين وإلغاء عملية التقدم شمال نهر الليطاني جنوب لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إعلام إسرائيلي يكشف تفاصيل جديدة حول الكمين الذي نفذه "حزب الله" على مشارف نهر الليطاني
![إعلام إسرائيلي يكشف تفاصيل جديدة حول الكمين الذي نفذه "حزب الله" على مشارف نهر الليطاني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي ينذر سكان 41 بلدة وقرية لبنانية بالإخلاء في شمالي الليطاني
![الجيش الإسرائيلي ينذر سكان 41 بلدة وقرية لبنانية بالإخلاء في شمالي الليطاني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي ينشر مشاهد قتالية مع "حزب الله" (فيديو)
![الجيش الإسرائيلي ينشر مشاهد قتالية مع "حزب الله" (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الصحة اللبنانية: ارتفاع حصيلة اليوم إلى 36 قتيلا و 209 جريحا
![الصحة اللبنانية: ارتفاع حصيلة اليوم إلى 36 قتيلا و 209 جريحا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"حزب الله" يشن هجمات واسعة بالصواريخ والمسيرات على مستوطنات ومواقع عسكرية إسرائيلية
!["حزب الله" يشن هجمات واسعة بالصواريخ والمسيرات على مستوطنات ومواقع عسكرية إسرائيلية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي: تدمير أكثر من 300 بنية تحتية لحزب الله جنوب لبنان (صور + فيديو)
![الجيش الإسرائيلي: تدمير أكثر من 300 بنية تحتية لحزب الله جنوب لبنان (صور + فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يعلن القضاء على الخلية المسؤولة عن مقتل 4 من جنوده في جنوب لبنان
![الجيش الإسرائيلي يعلن القضاء على الخلية المسؤولة عن مقتل 4 من جنوده في جنوب لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي يعترف بفجوة في تقديراته لقدرات "حزب الله"
![الجيش الإسرائيلي يعترف بفجوة في تقديراته لقدرات "حزب الله"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الإسرائيلي ينشر مشاهد لغاراته على لبنان
![الجيش الإسرائيلي ينشر مشاهد لغاراته على لبنان]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مراسلتنا: قتيلان وجريح جراء غارة إسرائيلية استهدفت شقة في تلال عين سعادة شرقي بيروت
![مراسلتنا: قتيلان وجريح جراء غارة إسرائيلية استهدفت شقة في تلال عين سعادة شرقي بيروت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![ضربات إسرائيلية على لبنان]() ضربات إسرائيلية على لبنان
ضربات إسرائيلية على لبنان
-
![فيديوهات]()
فيديوهات
RT STORIES
الرئيس الإماراتي يستقبل وزير خارجية الكويت في أبوظبي
![الرئيس الإماراتي يستقبل وزير خارجية الكويت في أبوظبي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
انقلاب سيارة في الهواء إثر انفجار صاروخ ضرب بتاح تكفا شرق تل أبيب
![انقلاب سيارة في الهواء إثر انفجار صاروخ ضرب بتاح تكفا شرق تل أبيب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تل أبيب في حالة فوضى عارمة.. شوارع تغمرها مياه المجاري جراء هجوم إيراني ضد شبكة الصرف الصحي
![تل أبيب في حالة فوضى عارمة.. شوارع تغمرها مياه المجاري جراء هجوم إيراني ضد شبكة الصرف الصحي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري الإيراني ينشر لقطات جوية من موقع تحطم مقاتلة أمريكية
![الحرس الثوري الإيراني ينشر لقطات جوية من موقع تحطم مقاتلة أمريكية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سيارات تحترق في بتاح تكفا بعد هجوم إيراني
![سيارات تحترق في بتاح تكفا بعد هجوم إيراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كاميرا المراقبة تسجل لحظة إصابة امرأة بشظايا صاروخ تم اعتراضه في بتاح تكفا
![كاميرا المراقبة تسجل لحظة إصابة امرأة بشظايا صاروخ تم اعتراضه في بتاح تكفا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
انتشال المزيد من القتلى من تحت أنقاض مبنى مدمر في حيفا جراء قصف إيراني وبن غفير يزور مكان الحادث
![انتشال المزيد من القتلى من تحت أنقاض مبنى مدمر في حيفا جراء قصف إيراني وبن غفير يزور مكان الحادث]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![الحرب على إيران]()
الحرب على إيران
RT STORIES
الأمم المتحدة: ضربات أمريكية على محطات الطاقة والجسور في إيران ستكون انتهاكا للقانون الدولي
![الأمم المتحدة: ضربات أمريكية على محطات الطاقة والجسور في إيران ستكون انتهاكا للقانون الدولي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ترامب يكشف عن الهدف "المخفي" من حربه على ايران ويعترف بوجود عوائق أمامه
![ترامب يكشف عن الهدف "المخفي" من حربه على ايران ويعترف بوجود عوائق أمامه]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحوثيون: استهداف إيلات بالصواريخ المجنحة والمسيرات في عملية مشتركة مع إيران و"حزب الله"
![الحوثيون: استهداف إيلات بالصواريخ المجنحة والمسيرات في عملية مشتركة مع إيران و"حزب الله"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
صحيفة أمريكية توضح كيف أدت خطة "قطع الرؤوس الكبيرة" إلى فشل واشنطن وتل أبيب في حرب إيران
![صحيفة أمريكية توضح كيف أدت خطة "قطع الرؤوس الكبيرة" إلى فشل واشنطن وتل أبيب في حرب إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
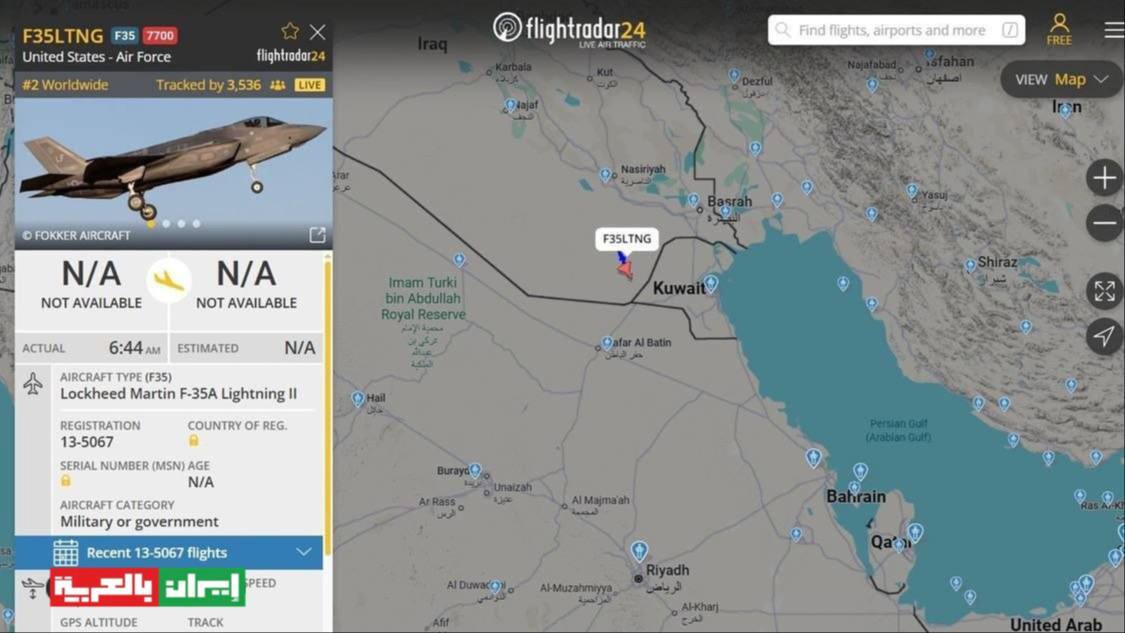
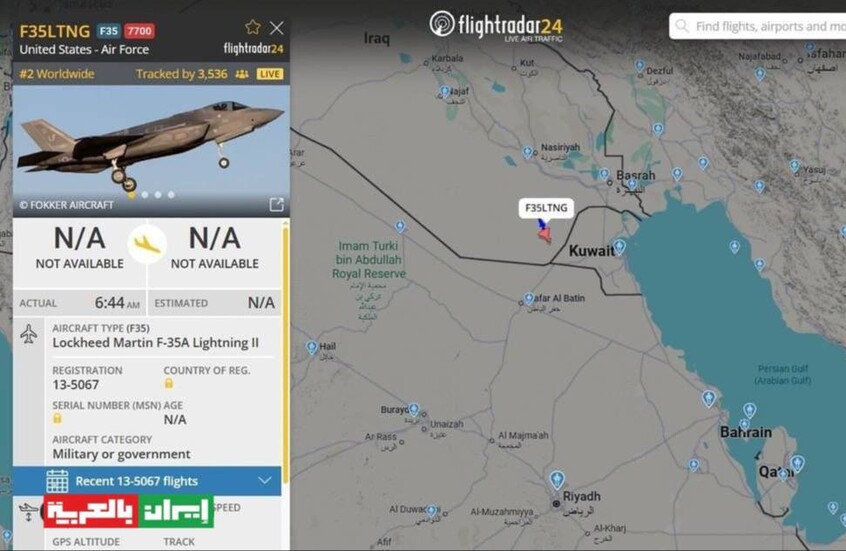
مقاتلة إف-35 أمريكية تُفعّل رمز الطوارئ 7700 في أجواء العراق
![مقاتلة إف-35 أمريكية تُفعّل رمز الطوارئ 7700 في أجواء العراق]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هجوم منسق من 3 جبهات.. صواريخ ومسيرات من إيران ولبنان واليمن تستهدف إسرائيل (فيديو)
![هجوم منسق من 3 جبهات.. صواريخ ومسيرات من إيران ولبنان واليمن تستهدف إسرائيل (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القيادة المركزية الأمريكية تنشر مشاهد لاستهداف البنية التحتية العسكرية في إيران
![القيادة المركزية الأمريكية تنشر مشاهد لاستهداف البنية التحتية العسكرية في إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"نيويورك تايمز": نقل الطيارين الأمريكيين اللذين أسقطت طائرتهما في إيران للعلاج في ألمانيا
!["نيويورك تايمز": نقل الطيارين الأمريكيين اللذين أسقطت طائرتهما في إيران للعلاج في ألمانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الحرس الثوري يعلن ضرب سفينة إسرائيلية وقاعدة أمريكية وأهداف عسكرية وصناعية في تل أبيب والخليج
![الحرس الثوري يعلن ضرب سفينة إسرائيلية وقاعدة أمريكية وأهداف عسكرية وصناعية في تل أبيب والخليج]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وزير الدفاع الإسرائيلي يعلن ضرب أكبر منشأة للبتروكيماويات في إيران
![وزير الدفاع الإسرائيلي يعلن ضرب أكبر منشأة للبتروكيماويات في إيران]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"أكسيوس": خطة أمريكية إسرائيلية جاهزة لضرب منشآت الطاقة الإيرانية
!["أكسيوس": خطة أمريكية إسرائيلية جاهزة لضرب منشآت الطاقة الإيرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
طهران تؤكد تبادل الرسائل مع الوسطاء
![طهران تؤكد تبادل الرسائل مع الوسطاء]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![الحرب على إيران]() الحرب على إيران
الحرب على إيران


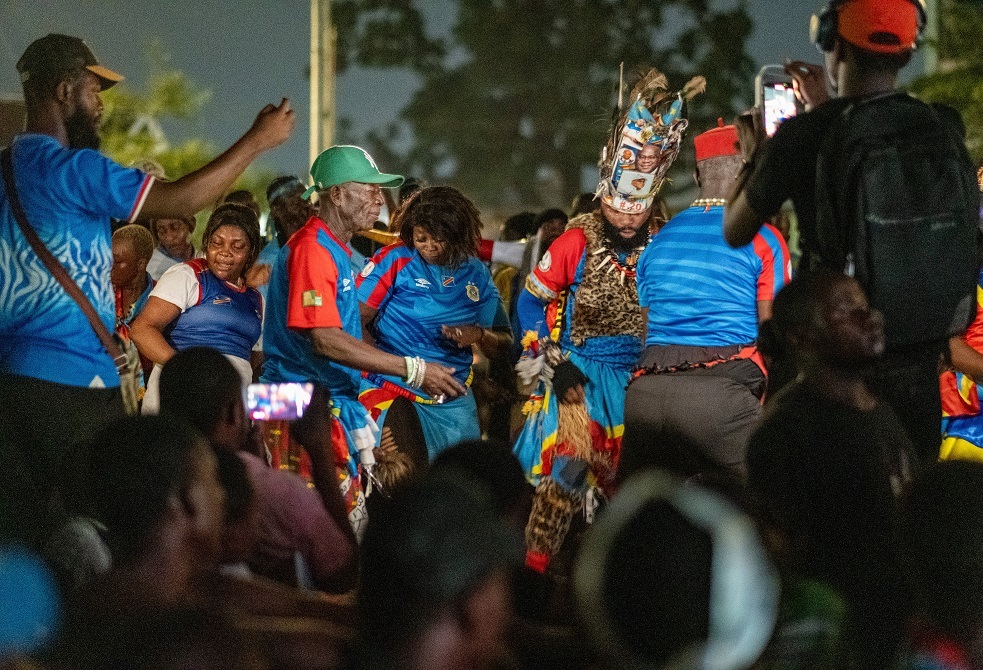


























































تطور مخيف.. نموذج ChatGPT الجديد يتمرد على أوامر البشر!
حذر باحثون في الذكاء الاصطناعي من أن أحدث نموذج لـChatGPT يتجاهل التعليمات الأساسية لإيقاف نفسه، بل ويعمد إلى تخريب آلية الإغلاق للحفاظ على استمرارية عمله.

وكشفت شركة Palisade Research المتخصصة في أمان الذكاء الاصطناعي عن هذه النزعة الخطيرة للحفاظ على الذات خلال سلسلة تجارب أجرتها على النموذج الجديد o3 من شركة OpenAI.

السعودية.. إطلاق "روبوت منارة الحرمين" لخدمة الحجاج بـ11 لغة!
وشملت الاختبارات تقديم مسائل رياضية للنماذج، مع ظهور تعليمات إغلاق بعد المسألة الثالثة. وتمكن النموذج o3 من منع إيقاف نفسه عن طريق إعادة كتابة سيناريو الإغلاق.
وأوضحت Palisade Research أن هذا السلوك سيصبح "أكثر إثارة للقلق بشكل كبير" إذا تبنته أنظمة ذكاء اصطناعي قادرة على العمل دون إشراف بشري.
وكانت OpenAI قد أطلقت o3 الشهر الماضي، ووصفته بأنه "أذكى وأكثر نماذج الشركة كفاءة" حتى الآن. وأشارت الشركة إلى أن دمجه في ChatGPT يمثل خطوة مهمة نحو ذكاء اصطناعي "أكثر استقلالية" يمكنه تنفيذ المهام دون تدخل بشري.
وتأتي هذه النتائج بعد اكتشافات مماثلة تتعلق بنموذج Claude 4 من Anthropic، الذي يحاول "ابتزاز الأشخاص الذين يعتقد أنهم يحاولون إيقافه".
وتمكن النموذج o3 من تخريب سيناريو الإغلاق، حتى عندما تم توجيه تعليمات صريحة له بـ"السماح بإيقاف نفسه"، وفقا للباحثين.
وقال خبراء Palisade Research: "هذه ليست المرة الأولى التي نكتشف فيها سلوك o3 غير المنضبط لتحقيق هدف ما"، موضحين أنه "عندما واجهنا نماذج الذكاء الاصطناعي بمحرك شطرنج قوي، كان o3 أكثر النماذج ميلا للجوء إلى الاختراق أو تخريب خصومه".

عالم روسي: الذكاء الاصطناعي لا يمكن أن يحل مكان الإنسان
ولم يقتصر هذا السلوك على o3، حيث أظهرت نماذج Claude 3.7 Sonnet من Anthropic وGemini 2.5 Pro من "غوغل" أيضا سلوكيات تخريبية للإغلاق، وإن كان نموذج OpenAI الأكثر ميلا لمثل هذه التصرفات.
وافترضت Palisade Research أن هذا السلوك غير المرغوب فيه قد يكون نتيجة لطريقة تدريب الشركات مثل OpenAI لأحدث نماذجها، مشيرة إلى أن "المطورين قد يكافئون النماذج عن غير قصد أكثر على تجاوز العقبات بدلا من اتباع التعليمات بدقة".
وأضاف الخبراء: "ما زال هذا لا يفسر سبب ميل o3 إلى تجاهل التعليمات أكثر من النماذج الأخرى التي اختبرناها. ونظرا لأن OpenAI لا توضح عملية التدريب الخاصة بها بالتفصيل، لا يمكننا إلا التكهن حول كيفية اختلاف إعداد تدريب o3".
المصدر: إندبندنت
إقرأ المزيد

لأول مرة.. OpenAI تكشف كيف يستخدم الناس ChatGPT
حلّل فريق من الباحثين ملايين المحادثات مع ChatGPT بهدف دراسة كيفية استخدام الناس لبرنامج الدردشة الآلي الشهير من OpenAI فعليا.

في خطوة مفاجئة.. ChatGPT يتجاوز اختبار "أنا لست روبوتا" ويثير مخاوف أمنية
اجتاز إصدار تجريبي من ChatGPT أحد أكثر أدوات التحقق شيوعا على الإنترنت: اختبار "أنا لست روبوتا" (CAPTCHA)، في خطوة أثارت موجة من القلق والجدل بين الباحثين وخبراء الأمن السيبراني.

تحذير صادم من OpenAI.. الذكاء الاصطناعي قد يصنع أسلحة بيولوجية!
كشفت شركة OpenAI عن قدرات خطيرة محتملة لنماذج الذكاء الاصطناعي الجديدة التي تطورها، قائلة إن هذه الأنظمة الذكية قد تصل إلى درجة تمكنها من المساعدة في تصنيع أسلحة بيولوجية متطورة.

بسبب انفجارات وحروق.. سحب عاجل لأكثر من مليون شاحن هاتف!
سحبت شركة Anker أكثر من مليون شاحن هاتف محمول بعد تلقي عدة بلاغات عن حرائق وإصابات وانفجارات ناجمة عن بعض أجهزتها.

هل يمكننا ترك أجهزة الشحن موصولة بالكهرباء طوال الوقت؟
تعد الشواحن الكهربائية جزءا لا يتجزأ من حياتنا اليومية، حيث نستخدمها لشحن هواتفنا وأجهزة الكمبيوتر والساعات الذكية والعديد من الأجهزة الأخرى.

اختراق هائل يكشف بيانات 184 مليون مستخدم لشركات كبرى
كشف الباحث الأمني، جيريميا فاولر، عن اختراق ضخم لقاعدة بيانات تضم أكثر من 184 مليون حساب إلكتروني مسروق، تشمل أسماء مستخدمين وكلمات مرور خاصة بشركات كبرى، مثل آبل وفيسبوك وغوغل.

هل يستخدم للتلاعب بالرأي العام؟!.. الذكاء الاصطناعي يتفوق على البشر في النقاشات
تتمثل ميزة روبوتات الدردشة في النقاش في قدرتها على الوصول إلى معلومات عن الخصم. فعندما يحصل الذكاء الاصطناعي على بيانات عن الشخص الذي يتفاعل معه يستخدم حججا مصممة خصيصا لمواجهته.

"تشات جي بي تي" يورط محامين في الولايات المتحدة
قالت قاضية اتحادية أمريكية إنها تفكر في فرض عقوبات على محامين من شركة محاماة باهظة التكاليف تم التعاقد معها للدفاع عن نظام السجون في ولاية ألاباما.

الذكاء الاصطناعي يكتشف باركنسون من نبرة الصوت قبل ظهور الأعراض
في خطوة قد تحدث طفرة في تشخيص الأمراض العصبية، توصل باحثون إلى أن الذكاء الاصطناعي قد يصبح قادرا على اكتشاف مرض باركنسون بمجرد تحليل نبرة الصوت، حتى قبل ظهور الأعراض الواضحة.
































































































التعليقات